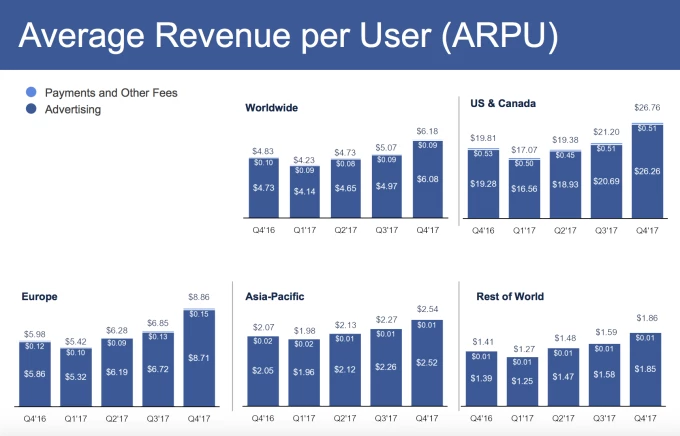
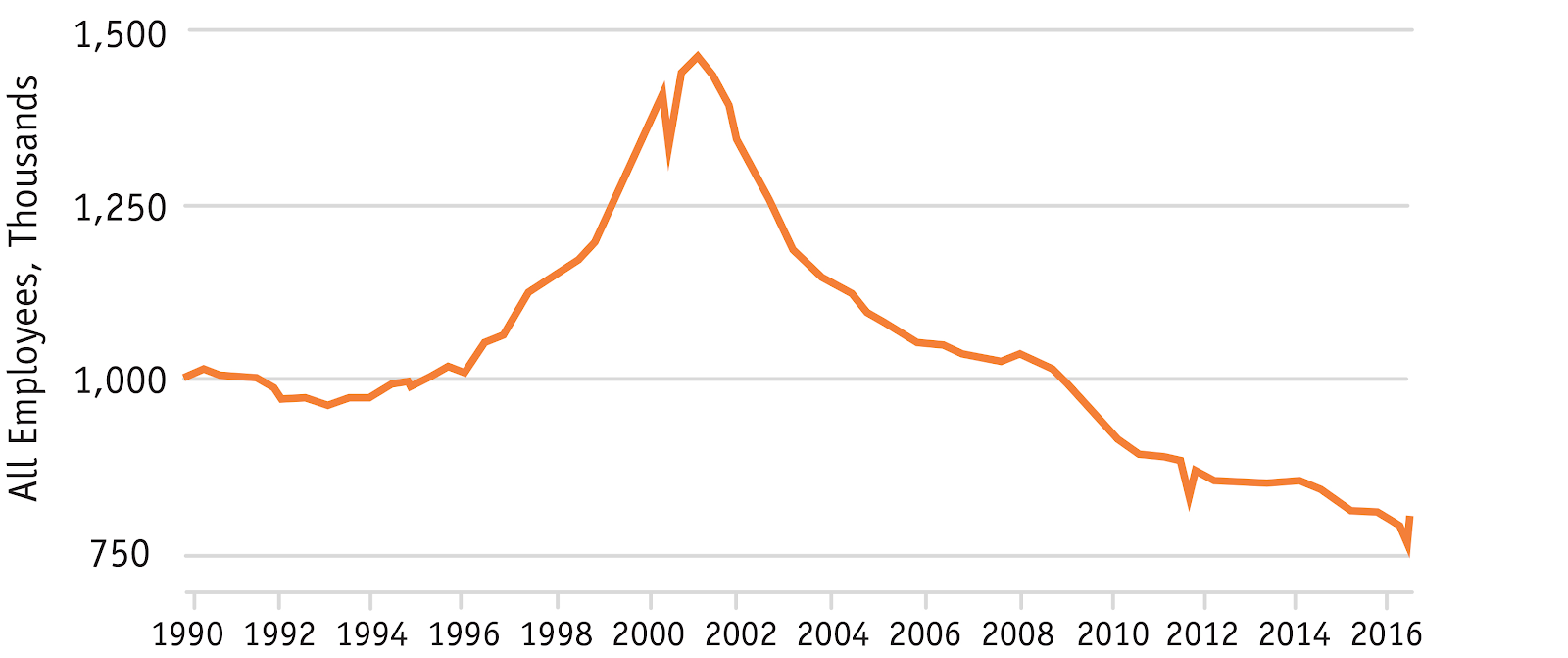
In principle, one might argue that open source AI and machine learning capabilities will allow small teams of people, using relatively small amounts of capital, to rapidly mimic the features and functions of any product.
However, in principle, one might also argue that gleaning insight, even when such small teams can use AI, will remain difficult, as the best insight will be generated by the smaller number of firms with huge amounts of aggregated past behavior.
To be sure, the ability to rapidly copy features and functions of new and existing products, using machine learning and artificial intelligence, will be widely possible.
In many ways, that is simply an intensification of current trends, where cheap and plentiful computing resources allow smaller teams to move fast, consuming less capital, than would have been required a few decades ago.
Open source helps, too. WhatsApp was able to build a global messaging system that served 900M users with just 50 engineers, compared to the thousands of engineers that were needed for prior generations of messaging systems, says Gianluca Mauro, AI Academy founder.
The same thing will happen as AI tools likewise are open sourced, allowing small teams of engineers to build state-of-the-art AI systems, he argues. That is going to mean that relatively-routine features and functions of any product will rapidly be copied by competitors.
So is that a source of value? Maybe, but maybe not as much as you might think.
The corollary is perhaps that value will be created not by firms able to apply AI to business processes, but to entities that own huge data stores. If the ability to create code, and therefore create features and functions, essentially is commoditized, unique value will then be possible when some entities are able to mine bigger and different stores of past behavior.
The reason is simple. Creation of predictive models will be more accurate when using huge stores of highly-granular past history. If the value of AI is the ability to create insights, then the owners of the most relevant data should be able to glean better insights.
Many important product features and functions, even those dependent on AI, will be capable of being reverse engineered at relatively low cost. As always with intellectual property concepts, the key is that it will be lawful to create a particular implementation of an idea or function, if unlawful to implement an idea, function or process in exactly the same way as another provider.
Almost by definition, then, the biggest entities, with the greatest number of interactions, sessions, transactions or queries, will have the biggest opportunities to create insights. Almost by definition, small firms will possess little internally-owned data of this type.
The great potential “leveler” then becomes the ability to lawfully use data stores owned by the biggest owners of data. Privacy laws might prevent that, however. In the coming AI era, there might still be trend toward bigness, for that reason.