Some might argue it is way too early to worry about a slowdown in large language model performance improvement rates. But some already voice concern, as OpenAI appears to see a slowdown in rates of improvement.
Gemini rates of improvement might also have slowed, and Anthropic might be facing similar challenges.
To be sure, generative artificial intelligence language model size has so far shown a correlation with performance. More inputs--such as larger model size--have resulted in more output.
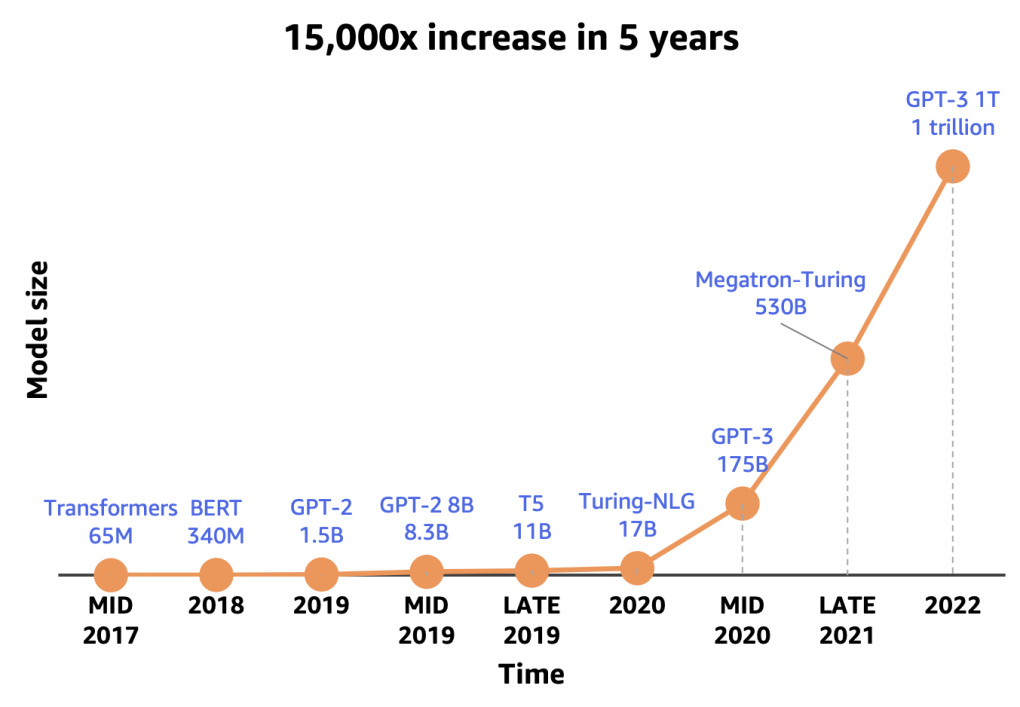
In other words, scaling laws exist for LLMs, as they do for machine learning and other aspects of AI. The issue is how long the current rates of improvement can last.
Scaling laws describe the relationships between a model’s performance and its key attributes: size (number of parameters), training data volume, and computational resources.
Scaling laws also imply that there are limits. At some point, the gains from improving inputs do not produce proportional output gains. So the issue is how soon LLMs might start to hit scaling law limits.
Aside from the cost implications of ever-larger model sizes, there is the related matter of the availability of training data. At some point, as with natural resources (oil, natural gas, copper, gold, silver, rare earth minerals), LLMs will have used all the accessible, low-cost data.
Other data exists, of course, but might be expensive to ingest. Think about the Library of Congress collection, for example. It is theoretically available, but the cost and time to “mine” it is likely more than any single LLM can afford. Nor is it likely any would-be provider could create (digitize) and supply such resources fast and affordably.
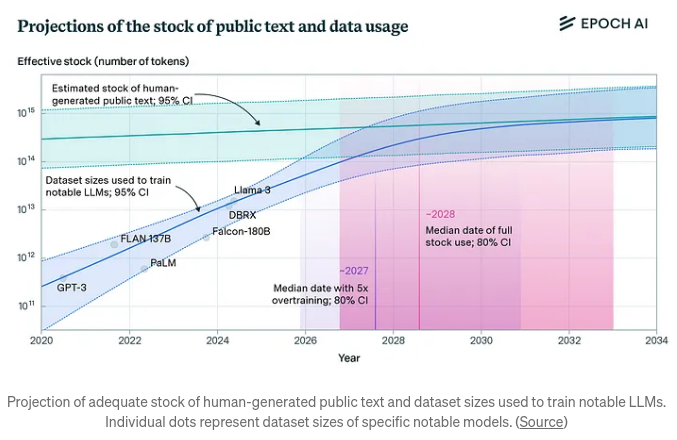
Consider the cost to digitize and make available the U.S. Library of Congress collection.
Digitization and metadata creation might cost $1 billion to $2 billion total, spread over five to 10 years, including the cost of digitizing and formatting:
Textual Content: $50 million - $500 million.
Photographic and Image Content: $75 million - $300 million.
Audio-Visual Content: $30 million - $120 million.
Metadata Creation and Tagging: Approximately 20-30% of total digitization costs ($200 million - $600 million).
I think the point is that with the speed of large language model updates (virtually continually in some cases, with planned model updates at least annually), no single LLM provider could afford to pay that much, and wait that long, for results.
Then there are the additional costs of data storage, maintenance, and infrastructure, which could range from $20 million to $50 million annually. Labor costs might be in the range of $10 million to $20 million annually as well.
Assuming the owner of the asset would want to license access to many other types of firms, sales, marketing, and customer support could add another $5 million to $10 million in annual costs.
The point is that even if an LLM wanted to spend $1 billion to $2 billion to gain access to the knowledge embedded in the U.S. Library of Congress, perhaps no LLM owner could afford to wait five years to a decade to derive the benefits.
And that is just one example of a scaling law limit. The other issues are energy consumption; computing intensity and model parameter size. At some point, diminishing returns from additional investment would occur.