One practical issue with edge computing is that not everybody uses the same definition of “edge,” even if everyone seems to agree edge computing means putting compute capabilities at the logical edge of a network.
As with many earlier architectural decisions app providers and transport providers must address, the issue boils down to “intelligence at the network edge” or “intelligence in the network core,” even if some functions might logically need to be centralized, while others can be distributed.
Consider even the hyperscale data center. Is such a computing facility, by definition located “at the network edge,” functionally a “core” or an “edge” function? Functionally, many would have to agree, it functions as a “core” element, not an edge element, though the webscale data center actually resides at a particular edge.
The important point is that for all the other endpoints, any particular data center actually “acts” like a “core” element, as it is remote.
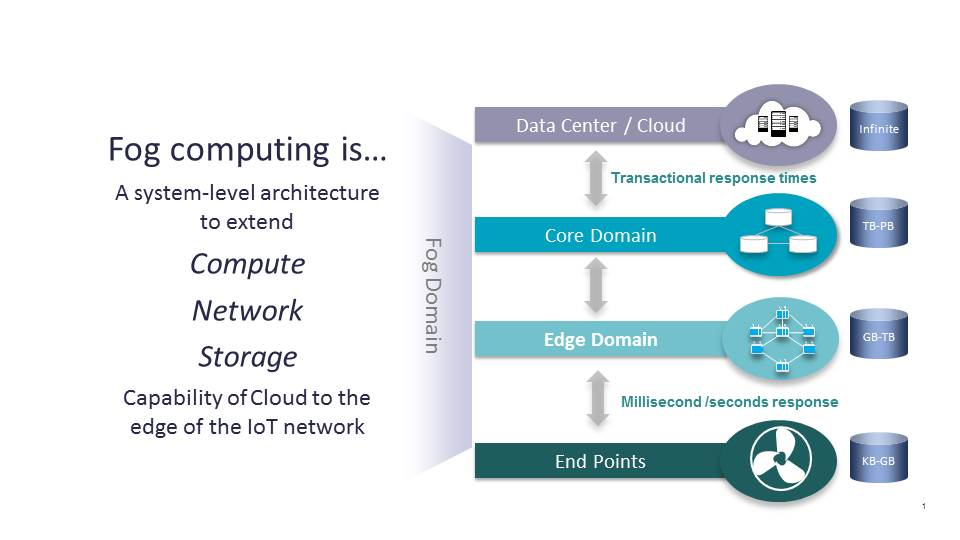
The Linux Foundation defines edge computing as “the delivery of computing capabilities to the logical extremes of a network in order to improve the performance, operating cost and reliability of applications and services.” The key concept there is the plurality of “extremes.”
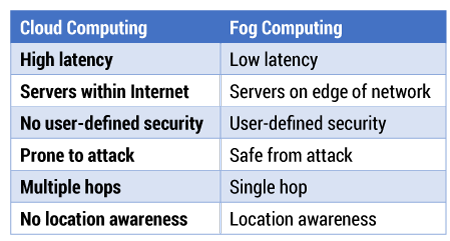
“Edge” only makes logical sense if “you” and your device are in the same local area as your compute facilities. In other words, your use of cloud computing happens generally as you would use a localized (metro) area network, and not as you use a wide area network.
In a real sense, you move from reliance on WAN-based hyperscale cloud centers to use of metro-level cloud facilities, and the issue is latency performance.
“By shortening the distance between devices and the cloud resources that serve them, and also reducing network hops, edge computing mitigates the latency and bandwidth constraints of today's Internet, ushering in new classes of applications,” the Linux Foundation definition states.
In practical terms, this means distributing new resources and software stacks along the path between today's centralized data centers and the increasingly large number of devices in the field, concentrated, in particular, but not exclusively, in close proximity to the last mile network, on both the infrastructure and device sides.
That has likely implications for where and how augmented intelligence (artificial intelligence) gets implemented in wide area networks. Just how much applied machine learning or augmented intelligence gets deployed in the core, as opposed to the edge, to create new service capabilities or gain operational advantages, remains an open question.
By definition, the whole advantage of edge computing is to avoid “hairpinning” (long transits of core networks), when local access can be provided. If so, when edge computing is widely deployed, the upside to using AI to groom traffic or reduce latency is less.
Nor is it entirely clear what new network-based capabilities can be created in the core network, using AI (for example), and which AI-based features actually are possible only, or implemented easier, at the edge. Some security features or location features might be possible only at the edge, some argue.
How to apply new technologies such as AI will remind you of similar debates and decisions that happened around “making core networks smarter” or relying on “smart edge” and simply building high-performance but “dumb” core networks. Those of you with long memories will recall those precise debates around use of ATM and IP for core networking.







{kind=link}