Anthropic (backed by Amazon and Alphabet) is expected to soon introduce a model that uses a slightly different approach to reasoning, allowing designers to tweak the computational effort of the model (essentially, high, medium or low), resulting in differences in how long and how much effort the model puts into reasoning about a particular problem.
Anthropic seems to be seeking a higher profile as an “enterprise” or “business” model supplier, whose products excel at the sorts of coding larger businesses require. For example, the new model is said to be “better at understanding complex code bases built from thousands of files and produces complete lines of code which work the first time.
That business user focus might also explain why Anthropic is putting effort into features that give developers more control over cost, speed and pricing.
The model uses more computational resources to calculate answers to hard questions. The AI model can also handle simpler tasks faster without the extra work, by acting like a traditional large language model, or LLM.
The new model might be important for other reasons. One advantage DeepSeek has apparently demonstrated is the way it can reason and learn from other models.
As was always to be expected, in a fast-moving AI field, important innovations by any single provider are going to be mimicked by other leading contenders as well.
One might well argue that Anthropic’s new model will provide an example of that, perhaps also illustrating the fact that the DeepSeek approach to reasoning also has been under development or investigation by multiple developers, to some extent.
An agentic AI system might not be as complicated an endeavor as Artificial General Intelligence (AGI), but it still is plenty complicated, involving a platform that integrates any number of capabilities including reasoning and problem solving; learning and adaptation; communication and understanding; perception; decision-making and planning; memory and knowledge management; goal setting; self-monitoring and reflection; human interaction; creativity; autonomy; security and adaptability.
As you would guess, each of these capabilities is embodied in different platforms or systems.
Reasoning and Problem-Solving:
Deductive Reasoning: Prolog, Expert Systems like CLIPS
Inductive Reasoning: Decision Trees, Bayesian Networks (e.g., Bayes Net Toolbox for MATLAB).
Abductive Reasoning: Systems like Sherlock (a framework for abductive reasoning).
Problem Decomposition: Planning systems like PDDL (Planning Domain Definition Language) used by planners like Fast Downward or LAMA
Learning and Adaptation:
Supervised Learning: TensorFlow, PyTorch for training models like CNNs, RNNs.
Unsupervised Learning: Autoencoders, K-means clustering implemented in scikit-learn.
Reinforcement Learning: OpenAI's Gym, DeepMind's MuJoCo, or libraries like Stable Baselines3
Communication and Understanding:
Large Language Models (LLMs): Hugging Face's Transformers with models like BERT, GPT-3, or custom implementations like those from xAI.
Transformers: Libraries like Hugging Face Transformers or Microsoft's DeepSpeed
Perception:
Image Recognition: OpenCV for basic operations, TensorFlow or PyTorch for CNNs like ResNet, YOLO for real-time object detection.
Speech Recognition: Kaldi, Mozilla's DeepSpeech, or cloud APIs like Google Cloud Speech-to-Text.
Sensor Integration: ROS (Robot Operating System) for robotics, or custom IoT frameworks for sensor data integration
Decision Making and Planning:
Rule-Based Systems: Drools, Jess for Java, or custom Python rule engines.
Neural Networks: Keras, TensorFlow, PyTorch for implementing various neural network architectures
Memory and Knowledge Management:
Short and Long-Term Memory: Implementations of LSTM or GRU in neural network libraries for memory, or dedicated systems like MemN2N (Memory Networks).
Knowledge Graphs: Neo4j for graph databases, or RDF systems like Apache Jena for semantic web applications.
Also required:
Goal Setting and Management: Custom implementations, or frameworks like BDI (Belief-Desire-Intention) agent architectures.
Ethical Decision Making: Not standardized but could involve rule engines with ethical guidelines or AI fairness toolkits like Fairlearn.
Self-Monitoring and Reflection: Could involve meta-learning frameworks or custom solutions using reinforcement learning for self-improvement.
Interaction with Humans and Other Systems: Dialog systems like Rasa or Microsoft Bot Framework, or APIs for system integration.
Creativity and Innovation: Generative Adversarial Networks (GANs) using TensorFlow or PyTorch, or systems like DALL-E for image generation.
Autonomy in Execution: Custom agents using frameworks like JADE (Java Agent DEvelopment Framework) or integrating with IoT platforms for physical actions.
Security and Privacy: Cryptographic libraries like OpenSSL, or frameworks ensuring differential privacy like TensorFlow Privacy.
Adaptability to New Environments or Tasks: Meta-learning approaches like MAML (Model-Agnostic Meta-Learning) or transfer learning capabilities in deep learning frameworks.
Reasoning and Problem-Solving:
Deductive Reasoning: For logical conclusions from known premises.
Inductive Reasoning: To infer general rules from specific instances.
Abductive Reasoning: For forming hypotheses from incomplete data.
Problem Decomposition: Ability to break down complex problems into manageable parts.
The point is that for all the legitimate attention now paid to large language models (generative AI), that field is but one among many that would have to be assembled and orchestrated to create agentic AI.
And even if an application-specific agent should be less complicated to create than AGI, it still is complicated.
Traditional models scale computation by generating more tokens, such as those utilizing chain-of-thought prompting.
What is different about latent reasoning is that it does not require specialized training data, operates effectively with small context windows and captures complex reasoning patterns that are challenging to express in words, observers say.
The authors describe a proof-of-concept model, scaled to 3.5 billion parameters and trained on 800 billion tokens that can can significantly improve performance on reasoning benchmarks, achieving results comparable to models with up to 50 billion parameters.
Aside from the potential impact on compute requirements, this approach also reduces need for access to training data, which likewise has cost implications. And it appears to rely more heavily on synthetic data as well, which, depending on one’s point of view, is a good thing or not so good a thing.
The model's ability to perform complex reasoning without relying on specialized training data sets broadens its applicability across various domains, reducing the need for task-specific data collection. In other words, it should be easier to modify models for industry verticals, functions and use cases.
Training costs should also be lower.
Also, dynamic adjustment of computational effort based on task complexity is possible. That allows balancing speed and compute costs for simple problems with depth of analysis for complicated problems.
Operating effectively with small context windows allows the model to handle tasks where context is limited, making it suitable for applications with constrained input sizes or where maintaining extensive context is impractical.
The importance of the approach is that it could offer advantages for models that are both computationally efficient and capable of sophisticated reasoning, yet less limited by concepts that cannot be easily expressed in language.
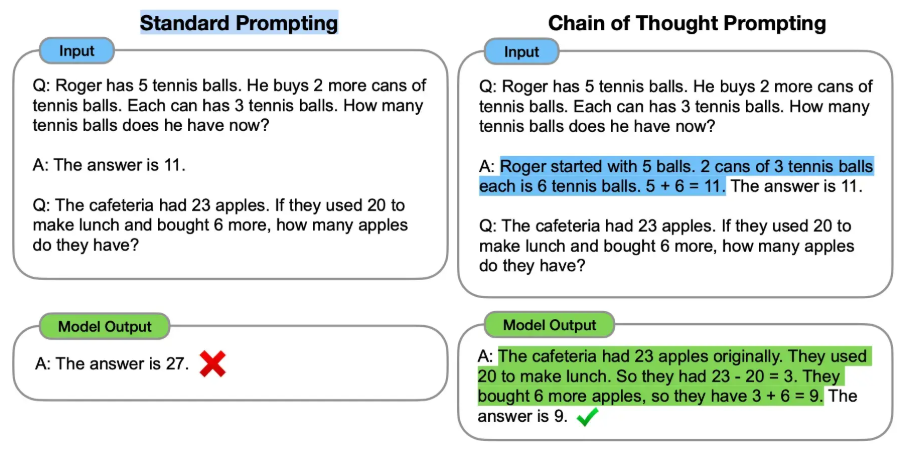
Latent reasoning differs from chain-of-thought (DeepSeek, for example) approaches primarily in how it handles the intermediate reasoning steps and computational scaling.
Chain of Thought uses explicit, human-readable intermediate steps to break down complex reasoning tasks. The model “documents” its thought process.
Latent Reasoning (Recurrent Depth Approach) does not explicitly write out its steps in natural language. Instead of generating additional tokens as intermediate steps, it refines internal representations through repeated processing.
For CoT, more reasoning means generating more tokens, which increases computational cost proportionally to the length of the reasoning process.
The latent reasoning model can iterate without increasing the output token length. This allows for more efficient scaling of reasoning.
CoT follows a fixed forward pass where each reasoning step is directly mapped to an output token sequence, while latent reasoning allows dynamic computation depth. So harder problems can use more internal iterations. In other words, the model can adjust computational effort based on problem complexity.
CoT works well when reasoning can be expressed in explicit language, but struggles with abstract problem-solving that doesn’t easily translate into words. Latent reasoning, on the other hand, can capture reasoning patterns that are difficult to articulate in natural language. It might therefore excel for tasks that require internal conceptual manipulation (high-level mathematics or abstract pattern recognition).
Sometimes “more” can be “less.” It might be akin to the U.S. Navy SEAL aphorism about slow is smooth; smooth is fast. In other words, being frantic often is not “fast.” In the same way, large language model use of chain of thought for prompting architecture (and reasoning) is a related example of using “more” processing to produce results for complicated queries using “less” total computation.
One reason some observers are a bit skeptical about DeepSeek cost claims (training and inference) is that the architecture, including use of "chain of thought" for inference, compared to the"simple inference" models used by ChatGPT, for example, require more processing, not less.
Chain of thought models break down problems into smaller steps, showing the reasoning at each step. So one might argue the smaller steps require less processing. On the other hand, more processing steps must occur.
So chain of thought models require more processing power and time compared to simple inference approaches, at least for uncomplicated queries. On the other hand, the obverse can be true for very-complex queries, one might argue. CoT might well succeed with a very-complex query, faster and more efficiently than a “simple inference” architecture might.
On the other hand, aCoT approach to prompt engineering also means there is no model fine-tuning required when adapting a model for a new set of tasks, in large part because standard prompts embed reasoning. In other words, CoT’s key concept is that by providing a few examples (or exemplars), where the reasoning process is explicitly shown, the LLM learns to include reasoning steps in its responses.
The point is that, in this case, more processing might well mean model training advantages (no fine-tuning required) but possibly also the ability to solve more-complex problems with less compute. Paradoxically, simpler compute, used to solve more-complex problems, might require less total compute.
Also, CoT enables smaller model sizes. Smaller models can be executed on less-capable hardware and platforms, for example, enabling a “lower cost” approach to model use. “Less” hardware also is possible. All of that has cost implications.
The key point is that CoT can lead to lower costs, even when requiring “more processing” for queries.
CoT prompting enables smaller models to perform complex reasoning tasks that were previously only possible with much larger models. So smaller, more efficient models can be used for tasks that once required massive language models.
Also, CoT reasoning capabilities can be transferred from larger models to smaller ones through knowledge distillation. For example, fine tuning a T5 XXL model (11 billion parameters) on CoT outputs from a much larger PaLM-540B model improved its accuracy on complex math problems from 8.11% to 21.99 percent.
CoT prompting can improve model performance across various tasks without the need for task-specific fine-tuning. This reduces the computational resources required for adapting models to new tasks.
By breaking down complex queries into smaller, manageable steps, CoT allows models to solve problems more efficiently. This can potentially reduce the overall computational load compared to attempting to solve the entire problem at once.
The ability to transfer CoT reasoning capabilities from larger to smaller models suggests that we may be able to create more compact, efficient models that retain advanced reasoning abilities of larger (and more expensive) models.